Category
Rastreo-e-indexacion
La indexación de aplicaciones para Android ya está disponible para todo el mundo
- junio 27th, 2014
- News, rastreo e indexación, resultados de búsqueda
- 0 Comments
¿Tienes una aplicación para Android además de tu sitio web? Ahora puedes conectar los dos para que los usuarios que efectúen búsquedas desde sus smartphones y tablets puedan encontrar fácilmente el contenido de tu aplicación y acceder a él.
Los enlaces profundos de aplicaciones en los resultados de búsqueda ayudan a tus usuarios a encontrar tu contenido con más facilidad, así como a volver a interactuar con la aplicación después de instalarla. Como propietario de un sitio, puedes mostrar a tus usuarios el contenido adecuado en el momento justo: al conectar páginas de tu sitio web a partes relevantes de la aplicación, puedes controlar cuándo se dirige a tus usuarios a la aplicación y cuándo visitan tu sitio web.

Cientos de aplicaciones ya han implementado la indexación. Esta semana anunciaremos en Google I/O un conjunto de características nuevas que facilitarán aún más la configuración de enlaces profundos en tu aplicación, la conexión de tu sitio a tu aplicación y el seguimiento del rendimiento y de los posibles errores.
Es fácil comenzar
Hemos simplificado en gran medida el proceso de indexación de enlaces profundos de tu aplicación. Si tu aplicación admite esquemas de enlaces profundos HTTP, tienes que hacer lo siguiente:Cuando indexemos tus URL, descubriremos e indexaremos las conexiones aplicación/sitio y los enlaces profundos de la aplicación pueden empezar a surgir en los resultados de búsqueda.
Podemos descubrir e indexar los enlaces profundos de tu aplicación por nuestra cuenta, pero te recomendamos que los publiques, especialmente si tu aplicación solo admite un esquema de enlaces profundos personalizado. Puedes publicarlos de dos formas:
- Inserta un elemento rel=alternate <link> en la sección <head> de cada página web o en tu sitemap para especificar los URI de la aplicación. Descubre cómo implementar estos métodos en nuestro sitio para desarrolladores.
- Usa la API de indexación de aplicaciones.
Hay algo más: hemos añadido una nueva característica a Herramientas para webmasters de Google que te ayudará a depurar los problemas que puedan surgir durante la indexación de páginas de aplicaciones. Te mostrará qué tipo de errores hemos detectado para los pares de página de aplicación-página web, junto con ejemplos de URIs de aplicación, para poder depurarlos:


Escrito por Mariya Moeva, Webmaster Trends Analyst. Publicado por Javier Pérez equipo de calidad de búsqueda .
Cómo crear la página de inicio adecuada para usuarios internacionales
- junio 16th, 2014
- consejos, News, rastreo e indexación
- 0 Comments
Hay tres formas de configurar la página de inicio o la página de destino para cuando los usuarios acceden a ella:
- mostrar el mismo contenido para todos los usuarios,
- permitirles escoger,
- publicar contenido en función de la localización y del idioma de los usuarios.
Mostrar el mismo contenido a los usuarios de todo el mundo
Con esta opción, tú decides publicar contenido específico para un país y un idioma determinados en la página de inicio o en la URL genérica (http://www.example.com). Este contenido estará disponible para cualquier usuario que haya accedido a esta URL directamente en el navegador o para aquellos que busquen específicamente esa URL. Tal como se indica más arriba, se debería poder acceder a todas las versiones de país e idioma en sus URL únicas.
Permitir a los usuarios elegir la versión local y el idioma que quieren
Con esta configuración, publicas una página de selección de país en la página de inicio o en la URL genérica para que los usuarios puedan escoger qué contenido quieren ver en función del país y del idioma. Todos los usuarios que escriban esta URL accederán a la misma página.Si implementas esta opción en el sitio internacional, recuerda utilizar la anotación x-default rel-alternate-hreflang para la página de selección de país, que se ha creado específicamente para este tipo de páginas. El valor x-default nos ayuda a reconocer las páginas que no son específicas de un idioma ni de una región.

Redirigir automáticamente a los usuarios o publicar de forma dinámica el contenido HTML adecuado en función de su configuración de ubicación y de idioma
Una tercera opción consiste en publicar automáticamente el contenido HTML adecuado para los usuarios en función de su configuración de ubicación y de idioma. Para ello, debes utilizar redireccionamientos 302 del entorno del servidor o publicar de forma dinámica el contenido HTML adecuado.Recuerda utilizar la anotación x-default rel-alternate-hreflang en la página de inicio o en la página genérica, aunque esta última sea una página de redireccionamiento a la que los usuarios no pueden acceder directamente.
Nota: Piensa en la opción de redirigir a los usuarios para los que no tienes una versión específica. Por ejemplo, usuarios francófonos en un sitio web que tiene versiones en inglés, español y chino. Muéstrales el contenido que consideres más adecuado.
Sea cual sea la configuración que escojas, debes asegurarte de que todas las páginas, incluidas las páginas de selección de país e idioma, cumplen lo siguiente:
- Tienen anotaciones rel-alternate-hreflang.
- Se encuentran accesibles para el rastreo y la indexación de Googlebot: no bloquees el rastreo ni la indexación de las páginas localizadas.
- Permite siempre que los usuarios cambien a la versión o al idioma local. Para ello, puedes utilizar un menú desplegable.
Acerca de las anotaciones rel-alternate-hreflang
Recuerda anotar todas tus páginas, sea cual sea el método que utilices. Ello permitirá que los motores de búsqueda muestren los resultados adecuados a tus usuarios fácilmente.Todas las páginas de selección de país y las páginas de inicio de publicación dinámica o que redirigen deberían utilizar x-default hreflang, que se ha diseñado específicamente para las páginas de inicio y las páginas de selección de país de redireccionamiento automático.
Por último, aquí tienes algunos recordatorios generales sobre las anotaciones rel-alternate-hreflang:
- Tus anotaciones deben confirmarse desde las otras páginas. Si la página A enlaza con la página B, la página B tiene que volver a enlazar con la página A. De lo contrario, es posible que las anotaciones no se interpreten correctamente.
- Las anotaciones deben hacer referencia a sí mismas. La página A debería utilizar los enlaces de la anotación rel-alternate-hreflang para sí misma.
- Puedes especificar las anotaciones rel-alternate-hreflang en el encabezado de HTTP, en la sección del encabezado del HTML o en un archivo de sitemap. Es muy recomendable que elijas solo una forma de implementar las anotaciones para evitar incoherencias y errores.
- El valor del atributo hreflang debe estar en formato ISO 639-1 para el idioma y en ISO 3166-1 Alpha 2 para la región. No puedes especificar solo la región. Si deseas configurar tu sitio solo para un país, utiliza la función de orientación geográfica en Herramientas para webmasters de Google.
Simplificar los movimientos de sitio
- junio 6th, 2014
- News, rastreo e indexación
- 0 Comments
Aspectos básicos de los movimientos de sitio
En términos generales, un movimiento de sitio es uno de los dos tipos de migración de contenidos:- Movimientos de sitio sin cambios de URL. Solo se cambia la infraestructura subyacente del sitio web sin ningún cambio visible en la estructura de la URL. Por ejemplo, puedes mover www.example.com a un proveedor de host diferente y mantener al mismo tiempo las mismas URL y la misma estructura de sitio que en www.example.com.
- Movimientos de sitio con cambios de URL. En este caso, las URL del sitio web cambian de muchos modos:
- El protocolo: de http://www.example.com a https://www.example.com
- El nombre del dominio: de example.com a example.net
- Las rutas de la URL: de http://example.com/page.php?id=1 a http://example.com/widget
Mover el sitio y cambiar a un diseño web adaptativo
Una cuestión relacionada cada vez más habitual con que nos encontramos es cómo se puede mover un sitio web y pasar de tener URL independientes para móviles o una publicación dinámica a usar un diseño web adaptativo. Para ayudarte a implementar este cambio de configuración, consulta esta página nueva en nuestro sitio de recomendaciones para smartphones.Además, como siempre, pregunta en nuestros Foros de ayuda para webmasters si tienes más preguntas.
Comprender mejor las páginas web
- mayo 23rd, 2014
- accesibilidad, News, rastreo e indexación
- 0 Comments
En 1998, cuando nuestros servidores funcionaban desde el garaje de Susan Wojcicki, no nos preocupábamos para nada de JavaScript ni de CSS. Estos recursos se utilizaban poco, y JavaScript servía para hacer que los elementos de las páginas... parpadearan. Las cosas han cambiado mucho desde entonces. La Web está repleta de sitios web increíbles, dinámicos y sofisticados que usan mucho JavaScript. Hoy nos centraremos en nuestra capacidad de procesar sitios web más sofisticados, es decir, de ver tu contenido de una forma más parecida a cómo lo hacen los navegadores web modernos, de incluir recursos externos, de ejecutar JavaScript y de aplicar CSS.
Hasta ahora solo nos fijábamos en el contenido textual sin editar procedente del cuerpo de respuesta de HTTP, y no interpretábamos lo que veía un navegador normal que ejecutara JavaScript. Cuando empezaron a aparecer páginas con valioso contenido procesado por JavaScript, los usuarios que hacían búsquedas no podían acceder a ese contenido, lo cual era muy negativo tanto para los usuarios como para los webmasters.
Para solucionar ese problema, decidimos intentar comprender las páginas mediante la ejecución de JavaScript. No era tarea fácil, dada la envergadura de la Web actual, pero pensamos que valía la pena intentarlo. Poco a poco hemos ido mejorando la forma de hacerlo. Durante los últimos meses, nuestro sistema de indexación ha procesado un número sustancial de páginas web de forma más parecida a cómo lo haría el navegador de un usuario normal con JavaScript activado.
Hay algunas cosas que a veces fallan durante el procesamiento, lo que puede afectar negativamente a los resultados de búsqueda de tu sitio. A continuación detallamos algunos problemas potenciales y, siempre que sea posible, la forma de evitar que se produzcan:
- Si se bloquean recursos como JavaScript o CSS en diferentes archivos (por ejemplo, con robots.txt) y Googlebot no puede recuperarlos, nuestros sistemas de indexación no podrán ver tu sitio como un usuario común. Te recomendamos que permitas que Googlebot recupere datos en JavaScript y CSS para que tu contenido se pueda indexar mejor. Esto es especialmente importante en sitios web para móviles, en los que los recursos externos como CSS y JavaScript contribuyen a que nuestros algoritmos comprendan que las páginas están optimizadas para móviles.
- Si nuestro servidor web no puede gestionar el volumen de solicitudes de rastreo de recursos, nuestra capacidad de procesar tus páginas se puede ver afectada negativamente. Si quieres asegurarte de que Google pueda procesar tus páginas, comprueba que los servidores puedan gestionar las solicitudes de rastreo de los recursos.
- Siempre es recomendable que tu sitio tenga una degradación elegante. Esto permite que los usuarios disfruten de tu contenido aunque su navegador no disponga de las implementaciones de JavaScript compatibles. También es útil para los visitantes que tienen JavaScript inhabilitado o desactivado, así como para los motores de búsqueda que aún no pueden ejecutar JavaScript.
- A veces, ejecutar JavaScript puede ser un proceso demasiado opaco o complejo para nosotros, en cuyo caso no podremos procesar la página por completo ni de la forma adecuada.
- Algunos recursos de JavaScript eliminan contenido de la página en vez de añadirlo, lo que nos impide indexar dicho contenido.
Para facilitar la depuración, estamos trabajando en una herramienta para ayudar a los webmasters a comprender mejor cómo procesa Google su sitio. Esperamos ponerla a tu disposición dentro de unos días en Herramientas para webmasters.
Si tienes alguna pregunta, visita nuestro foro de ayuda.
Escrito por Michael Xu, Ingeniero de Software, y Kazushi Nagayama, Analista de Tendencias de Webmasters, Publicado por Javier Pérez equipo de calidad de búsqueda.
Errores de rastreo de smartphones en Herramientas para webmasters de Google
- marzo 20th, 2014
- accesibilidad, herramientas para webmasters, móvil, News, rastreo e indexación
- 0 Comments
Algunos sitios web optimizados para smartphones están configurados de forma incorrecta, ya que no muestran a los usuarios que realizan búsquedas la información objeto de su consulta. Por ejemplo, a los usuarios de smartphones se les muestra una página de error o se les redirige a una página irrelevante, pero a los usuarios de ordenadores se les muestra el contenido que desean. Algunos de estos problemas, detectados por el robot de Google como errores de rastreo, dañan de forma significativa la experiencia del usuario en tu sitio web y son la base de algunos de nuestros cambios de clasificación recientemente anunciados para los resultados de búsqueda de smartphones.
A partir de hoy, puedes usar los Errores de rastreo ampliados en Herramientas para webmasters de Google para facilitar la identificación de las páginas de tus sitios que manifiestan estos tipos de problemas. Hemos incorporado una nueva pestaña de errores de smartphones en la que compartimos las páginas que hemos identificado con errores detectados únicamente con el robot de Google para smartphones.

- Errores de servidor: cuando el robot de Google obtiene un código de estado de error HTTP al rastrear la página.
- Errores de página no encontrada y errores 404 leves: una página puede mostrar un mensaje "no encontrado" al robot de Google, bien cuando ofrece un código de estado 404 HTTP o cuando se detecta que la página es una página de error leve.
- Redireccionamientos defectuosos: un redireccionamiento defectuoso es un error específico de smartphones que se produce cuando una página para ordenadores redirige a los usuarios de smartphones a una página que no guarda relación con su consulta. Un ejemplo típico de este tipo de error es cuando todas las páginas de un sitio para ordenadores redirigen a los usuarios de smartphones a la página principal del sitio optimizado para smartphones.
- URL bloqueadas: una URL bloqueada es aquella en la que el archivo robots.txt del sitio no permite de forma explícita que el robot de Google lleve a cabo el rastreo para smartphones. Por lo general, estas directivas de inhabilitación de robots.txt específicas para smartphones son erróneas. Debes investigar la configuración del servidor si ves URL bloqueadas identificadas en Herramientas para webmasters de Google.
Si solucionas los problemas que se muestran en Herramientas para webmasters de Google, puedes mejorar tu sitio para los usuarios y permitir que los algoritmos indexen mejor el contenido. Puedes obtener más información sobre cómo crear sitios web para smartphones y cómo solucionar los errores más frecuentes. Como siempre, si tienes cualquier duda, pregunta en nuestros foros.
Escrito por Pierre Far, Webmaster Trends Analyst, Publicado por Javier Pérez equipo de calidad de búsqueda de Google.
Video: Expandiendo tu sitio web a otros idiomas
- febrero 11th, 2014
- accesibilidad, consejos, News, rastreo e indexación, resultados de búsqueda, vídeo
- 0 Comments
Hemos grabado un vídeo para ayudar a los webmasters a expandir sus sitio a otros idiomas o variaciones de lenguaje basadas en el país. En este vídeo se habla de temas como el rel=”alternate” hreflang y como aplicarlo en un sitio multilingüe y / o multinacional.
Puedes ver el vídeo de principio a fin o saltar a la sección que te interese:
- Posibles problemas de búsqueda con sitios web internacionales
- Preguntas a plantearse antes de comenzar el proceso de internacionalización
- Tipos de internacionalización en sitios web
- rel=”alternate” hreflang y hreflang=”x-default”: explicación e implementación
- Buenas prácticas
- Recursos adicionales para el uso del hreflang:
- Artículo del centro de ayuda para webmasters rel=”alternate” hreflang y hreflang=”x-default”
- Más ayuda
- Gestión de sitios web multilingües
- Gestión de sitios web orientados a múltiples regiones
- Nuevo marcado para contenido multilingüe
- Presentamos el "x-default hreflang" para páginas de destino internacionales
- Preguntas frecuentes sobre internacionalización (ingles)
- Foro de ayuda para webmasters de Google
Buena suerte expandiendo tu sitio web a más idiomas
Escrito por Maile Ohye, Developer Programs Tech Lead. Publicado por Javier Pérez equipo de calidad de búsqueda de Google.
Un nuevo user-agent del robot de Google para rastrear contenido para smartphones
- enero 23rd, 2014
- móvil, News, rastreo e indexación
- 0 Comments
Un nuevo robot de Google para smartphones
Para poner remedio a esta situación y proporcionar un mayor control al webmaster, empezaremos a retirar "Googlebot-Mobile" para smartphones como user-agent dentro de unas 3 o 4 semanas. Tras realizar este cambio, el user-agent para smartphones se identificará simplemente como "Googlebot", pero todavía aparecerá "mobile" en algún lugar de la cadena del user-agent. Estos son los user-agents nuevos y los antiguos:El nuevo user-agent del robot de Google para smartphones:
Mozilla/5.0 (iPhone; CPU iPhone OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5376e Safari/8536.25 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
El user-agent de Googlebot-Mobile para smartphones que retiraremos en breve:
Mozilla/5.0 (iPhone; CPU iPhone OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5376e Safari/8536.25 (compatible; Googlebot-Mobile/2.1; +http://www.google.com/bot.html)
Este cambio solo afecta a Googlebot-Mobile para smartphones. El user-agent del robot de Google estándar no se modificará, y los otros dos rastreadores de Googlebot-Mobile seguirán haciendo referencia a los dispositivos telefónicos de gama baja en sus cadenas de user-agent. Aparecen a continuación a modo de referencia:
User-agent del robot de Google estándar:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Los dos user-agents de Googlebot-Mobile para teléfonos de gama baja:
SAMSUNG-SGH-E250/1.0 Profile/MIDP-2.0 Configuration/CLDC-1.1 UP.Browser/6.2.3.3.c.1.101 (GUI) MMP/2.0 (compatible; Googlebot-Mobile/2.1; +http://www.google.com/bot.html)DoCoMo/2.0 N905i(c100;TB;W24H16) (compatible; Googlebot-Mobile/2.1; +http://www.google.com/bot.html)
Puedes probar tu sitio con la función Explorar como Google de Herramientas para webmasters de Google; también encontrarás una lista completa de nuestros rastreadores actuales en el Centro de ayuda.
El rastreo y la indexación
Ten en cuenta esta cuestión importante sobre la actualización del user-agent: el nuevo rastreador del robot de Google para smartphones seguirá el robots.txt, la metaetiqueta de robots y las directivas de encabezado HTTP del robot de Google en lugar de seguir los mismos elementos de Googlebot-Mobile. Por ejemplo, cuando se implemente el nuevo rastreador, la directiva robots.txt bloqueará todo el rastreo del nuevo user-agent del robot de Google para smartphones y también del robot de Google estándar:User-agent: GooglebotLa directiva robots.txt bloqueará el rastreo de los rastreadores de Google para teléfonos de gama baja:
Disallow: /
User-agent: Googlebot-Mobile
Disallow: /
De acuerdo con nuestros análisis internos, esta actualización afecta a menos de un 0,001% de URLs y proporciona a los webmasters un mayor control sobre el rastreo y la indexación del contenido. Como siempre, si tienes alguna pregunta puedes hacer lo siguiente:
- leer nuestras recomendaciones para crear sitios optimizados para smartphone,
- obtener más información sobre el control del rastreo y la indexación del robot de Google,
- preguntar en los foros de ayuda para webmasters o visitar algunas de las conversaciones durante el horario de oficina del Centro para webmasters.
Errores de rastreo: la próxima generación
- abril 3rd, 2012
- herramientas para webmasters, News, rastreo e indexación
- 0 Comments
La función de errores de rastreo es una de las más populares de las Herramientas para webmasters de Google, y hoy vamos a lanzar varias mejoras bastante importantes que aumentarán su utilidad.
Anteriormente, solíamos informar de estos errores por URL, pero eso no tenía mucho sentido porque no eran errores específicos de URL individuales; de hecho, ni siquiera permitían que Googlebot solicitara una URL. Ahora realizamos un seguimiento de las tasas de fallo de cada tipo de error del sitio. También intentaremos enviarte alertas cuando estos errores sean lo suficientemente frecuentes que merezcan ser objeto de atención.
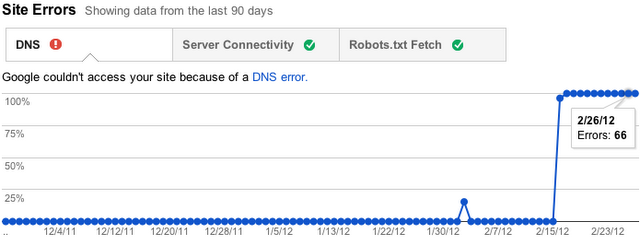

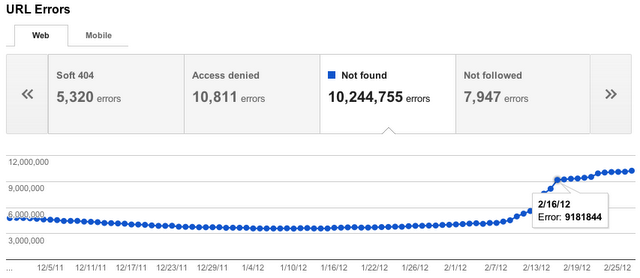
Para cada categoría, te ofreceremos los 1.000 errores que consideramos más importantes y que puedes resolver. Puedes ordenar y filtrar esos 1.000 errores principales, informarnos cuando creas haberlos solucionado y ver información detallada sobre ellos.

Para aquellos que consideran que la información detallada de 1.000 errores, junto con un recuento global total, no es suficiente, tenemos intención de añadir un acceso mediante programación (un API) que te permita descargar cada uno de los últimos errores que se hayan producido, por lo que nos gustaría que nos enviaras tus comentarios si necesitas más información al respecto.
Queríamos centrarnos realmente en los errores, por lo que te recomendamos que consultes la información sobre URL robotizadas que se mostrará en breve en la opción "Acceso de rastreadores" de la sección "Información del sitio".


Para determinar la clasificación de los errores, nos basamos en una serie de factores, incluido el hecho de si has incluido o no la URL en un sitemap, cuántos sitios incluyen enlaces a tu URL (y si alguno de ellos aparece también en tu sitio) y si la URL ha recibido tráfico de búsqueda recientemente.


